
Данная статья представляет собой свободный перевод раздела «Исследования» из доклада State of the Art 2022 (октябрь). Доклад State of the Art публикуется уже пятый год. Это подборка самых интересных вещей в мире AI, (конечно с точки зрения авторов). Отчет включает в себя несколько блоков:
- исследования — технические прорывы и возможности;
- промышленность — области коммерческого применения AI и его влияние на бизнес;
- политика — регулирование AI;
- безопасность — выявление и снижение рисков от использования будущих систем AI;
- прогнозы — что по мнению авторов произойдёт в 2023 году, а также проверка прогнозов, которые давались в прошлом году на 2022 год.
Ниже будет представлен только первый блок этого доклада — Исследования в области AI.
Прорывы в физических науках
Математика
- Исследователи DeepMind в этой статье предложили фреймворк для математиков, который помогает им с помощью машинного обучения выявлять закономерности и проверять гипотезы для доказательства новых теорем. Используя этот фреймворк исследователи DeepMind в сотрудничестве с математиками смогли доказать 40 летнюю гипотезу в теории представлений, а также доказать новую теорему в теории узлов.
- Здесь исследователи рассказали об ускорении алгоритмов умножения матриц с помощью обучения с подкреплением
Материаловедение
- В материаловедении исследователям удалось показать что точный функционал (Теории функционала плотности) может быть аппроксимирован с помощью нейронной сети.
Термоядерный синтез
- DeepMind обучили модель с подкреплением настраивать магнитные катушки, которые позволяют удерживать плазму чрезвычайно горячей, что позволяет обеспечивать ядерный синтез.
Биология/биохимия
- Прогнозирование структуры белков
- 1,5 года назад AlphaFold (DeepMind) раскрыла структуру белковой вселенной (Протеом). В 2022 году база была дополнена, были раскрыты предсказания почти для всех известных науке каталогизированных белков, это расширило базу данных более чем в 200(!) раз. Теперь остается только ждать прорывов в этой сфере — от открытия новых лекарств до прорывов в фундаментальной науки.
- Параллельно AlphaFold, сразу несколько исследовательских лабораторий применили языковые модели к прогнозированию белков. Работа Salesforce, работа Meta и др.
- Определение локализации белка с небольшой помощью машинного обучения
- Исследователи использовали эндогенную маркировку для определения локализации белка в клетках, затем они использовали алгоритмы кластеризации чтобы идентифицировать белковые сообщества и сформулировать гипотезы о неохарактеризованных белках. Марковская кластеризация на графе белковых взаимодействий успешно очертила функционально родственные белки. Эта информация была лишь частичным ответом о характере «неизвестных» белков, окончательный ответ формулировали люди, после проверки всех гипотез.
- Переработка пластика
- Исследователи из UT Austin разработали фермент, способный разлагать ПЭТ — тип пластика, на долю которого приходится 12% мировых твердых отходов. Нейронная сеть помогла команде решить, как модифицировать белковый каркас, чтобы создать новый фермент. Он отличается от предыдущего тем что разлагает 51 вид пластика быстрее и при менее высоких температурах. Также команде исследователей удалось ресинтезировать из остатков новый ПЭТ.
Исследования в области ML
Обнаружены системные проблемы воспроизводимости в ML
Исследователи из Принстона предупреждают о кризисе воспроизводимости в ML, из-за утечки данных. Утечка данных — это общий термин для ситуаций когда данные которые не должны быть доступны модели, на самом деле ей доступны. Самый распространенный пример — когда тестовые данные включены в обучающую выборку. Но утечка может быть более пагубной: когда в модели используются фичи, которые являются переменной от результата, или когда распределение на тестовых данных отличается от распределения на данных для обучения. В частности исследователи выбрали 17 тем для изучения и затронули 329 опубликованных статей, и обнаружили во всех утечки данных, в некоторых статьях результаты оказались чрезмерно оптимистичными. Авторы призывают бороться с данной проблемой с помощью использования специальных информационных листов, которые необходимо будет заполнить аналогично карточкам моделей.
Разработан новый BIG-bench тест
Исследователи из университетов (Оксфорд, и др.) изучили 1688 тестов для 406 задач AI и выявили что в частности языковые тесты имеют тенденцию быстро насыщаться, модели с легкостью достигают максимальных результатов. Быстрый прогресс опережает текущие бенчмарки, и это затрудняет определение фактического прогресса.
Новый тест BIG содержит 204 задания, которые проверяют возможности моделей от запоминания до многоэтапного рассуждения. На момент создания теста даже самые лучшие модели плохо работали на тесте BIG.
Появился новый взгляд на законы масштабирования языковых моделей
Ранее OpenAI опубликовала исследование в котором утверждалось что параметры модели должны расти быстрее размера тренировочного датасета. В этом году DeepMind обнаружила, что существующие языковые модели значительно недообучены, учитывая их большой размер. Они тренируют Chinchilla, уменьшенную в 4 раза версию их Gopher, используя в 4,6 раза больше данных, и обнаруживают, что Chinchilla превосходит Gopher и другие крупные модели на BIG-bench.
Выясненна еще одна особенность моделей, при их сильном масштабирования (увеличение параметров) наблюдается существенное улучшение качества работы модели (проявление эмерджентности), но с другой стороны у модели появляются небезопасные, нежелательные способности, в частности есть исследования, что большие модели начинают подражать человеческой лживости и токсичности. Тут. Тут.Скачок качества при увеличении моделей
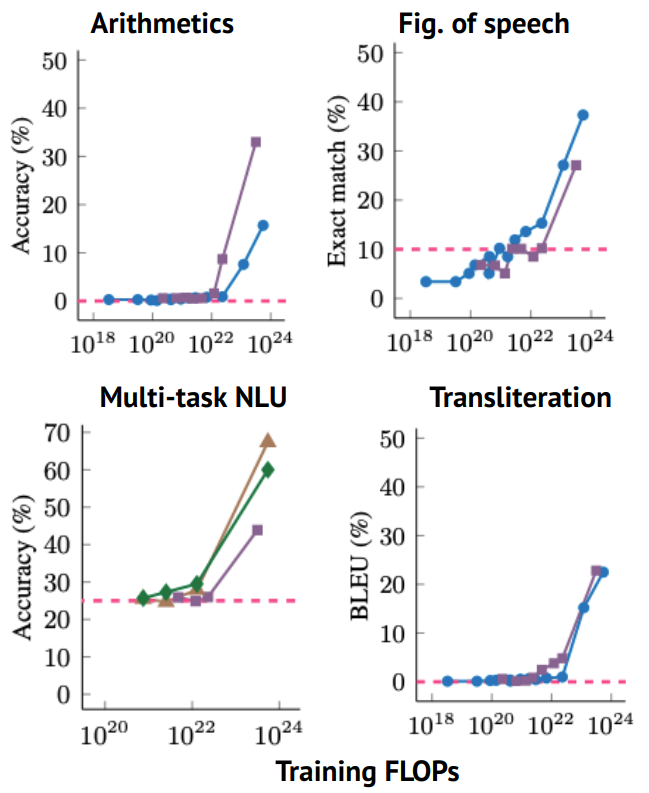
Определены три эпохи вычислений в машинном обучении
Исследование документирует невероятное ускорение требований к вычислительным ресурсам в машинном обучении. Оно определяет 3 эпохи машинного обучения. Эпоха до глубокого обучения (до 2010 г., тренировочные вычисления удваивались каждые 20 месяцев), эпоха глубокого обучения (2010–2015 гг., удвоение каждые 6 месяцев) и эра больших масштабов (с 2016 г. по настоящее время, скачок в 100–1000 раз) , а затем удваивается каждые 10 месяцев).
Диффузионные модели расширяются до других модальностей
В 2021 году, модели Diffusion обгоняли GAN в создании изображений по нескольким критериям. В 2022 они являются бесспорным SoTA для генерации изображения из текста, теперь модели распространяются в преобразование текста в видео, генерацию текста, аудио, молекулярное проектирование и многое другое.
Бушует битва за text-to-image
Вторая версия DALL-E от OpenAI (вышла в апреле 2022) показала значительный скачок качества генерируемых изображений. Вскоре после этого от Google появилась еще одна не менее впечатляющая модель, основанная на диффузии Imagen.
А вот модель Parti от Google пошла по другому пути. Вместо использования диффузионной модели, Parti рассматривает преобразование текста в изображение как простую задачу преобразования последовательности в последовательность, где прогнозируемая последовательность представляет собой пиксели в изображении. Примечательно, что по мере масштабирования количества параметров и обучающих данных в Parti модель приобретает новые возможности, такие как правописание.
Другие впечатляющие модели преобразования текста в изображение — GLIDE от OpenAI, Make-a-Scene от Meta и CogView2 от Tsinghua.
Появляются новые лаборатории AI, которые разрабатывают диффузионные text2image модели
Stability.ai и Midjourney появились, казалось бы, из ниоткуда с моделями преобразования текста в изображение, и они достойно конкурируют с моделями известных лабораторий искусственного интеллекта.
Гонка преобразования текста в видео началась
Исследования по преобразованию текста в видео на основе диффузионных моделей были начаты примерно в апреле 2022 года при участии Google и Университета Британской Колумбии. Но в конце сентября Meta и Google представили новые исследования, которые показали скачок качества.
Meta была первой из Big Tech в области преобразования текста в видео, выпустив Make-a-Video, диффузионную модель для создания видео.
По аналогии с преобразованием текста в изображение, Google опубликовал (менее чем через неделю) почти одновременно две модели: одну, основанную на диффузионной модели Imagen, и другую, не основанную на диффузионной модели, Phenaki. Она может динамически адаптировать видео с помощью дополнительных подсказок.
Модели больших компаний были клонированы сообществом
Модели от OpenAI и DeepMind были реализованы/клонированы/улучшены сообществом открытого исходного кода намного быстрее, чем ожидалось. Для GPT потребовалось 14 месяцев, для DALL-E — 15 мясяцев, для AlphaFold — 35 месяцев

Трансформеру исполнилось пять лет, но пока эффективной альтернативы не появилось
Attention слой в основе трансформера страдает квадратичной зависимостью от входных данных. Множество работ обещало решить эту проблему, но ни один метод не был принят. Это можно объяснить несколькими причинами:
- линейное ускорение полезно только для больших входных данных,
- новые методы вводят ограничения и делают модели менее универсальными,
- новые меры не приводят к фактической экономии затрат.
Битва между сверточными сетями и трансформерами продолжается
После того как Vision Transformers (ViT) и другие трансформеры в прошлом году получили SoTA в задачах компьютерного зрения стало понятно что эра ConvNets завершается. Но не тут-то было: работа Meta и Калифорнийского Университета в Беркли утверждает, что модернизация ConvNets дает преимущество перед ViT. Исследователи представили ConvNeXt, которая конкурирует с Swin Transformer и ViT.
Неизбежная унификация компьютерного зрения и языкового моделирования продолжается
Методы самообучения (self-supervised), используемые для обучения трансформеров на тексте, теперь перенесены почти как есть на изображения и достигают самых современных результатов на ImageNet-1K.
Появление мультимодальных трансформеров
Трансформеры, обученные конкретной задаче, могут использоваться для более широкого набора задач через fine tuning. Недавние работы показывают, что один трансформер может быть напрямую и эффективно обучен различным задачам в разных модальностях (многозадачное мультимодальное обучение).
Первые попытки создания универсальных многозадачных мультимодальных моделей были у Google еще в 2012 г, они создали модель, которая решала 8 задач с изображением, текстом и речью.Новая модель Gato от DeepMind выводит эти усилия на новый уровень: исследователи обучают трансформер для выполнения сотен задач в робототехнике, смоделированных средах, зрении и языке.
Чтобы обучить модель различным модальностям, все данные были сериализованы в последовательность токенов, встроенных в изученное векторное пространство.
Отдельно: с помощью data2vec для более узкого набора задач Meta разработала единую стратегию самообучения для разных модальностей. Но пока для каждой модальности используются разные трансформеры.
Трансформеры становятся по-настоящему кроссмодальными
Ожидалось что трансформеры выйдут за рамки NLP, чтобы достичь успехов в компьютерном зрении. Но за прошедший год стало понятно, что трансформеры являются кандидатами на архитектуру общего назначения. Анализ статей о трансформерах в 2022 году показывает, насколько повсеместной стала эта модельная архитектура.
Интеллектуальные агенты и роботы
OpenAI использует Minecraft в качестве полигона для интеллектуальных агентов
Исследователи собрали 2000 часов видео с размеченными действиями мышки и клавиатуры, на этих данных натренировали модель, которая предсказывает по предыдущему и следующему видеокадру какое действие было совершено (какая кнопка нажата). С помощью этой модели они разметили 70000 часов доступного видео из интернета, и уже на этих данных научили другую модель предсказывать действие, имея в распоряжении только предыдущий кадр. Интеллектуальный агент научился крафтить алмазы (эта задача у человека в среднем занимает 20 минут — 24000 действий). В своей работе исследователи показали что достичь таких результатов с нуля было очень трудно, и использование имитационного обучения сильно помогло обучить агента.
Большие языковые модели помогают роботам выполнять разнообразные и неоднозначные инструкции
Благодаря широкому спектру возможностей больших языковых моделей, они в принципе могут попросить роботов выполнять любую задачу, объясняя свои действия на естественном языке. Но у языковых моделей мало контекстуальных знаний об окружающей среде робота и его способностях, что делает их объяснения, как правило, невыполнимыми для робота. PaLM-SayCan решает эту проблему.
Допустим мы пролили воду и просим робота “Я пролил воду, ты можешь мне помочь?” Модель PaLM от Google может сгенерировать набор абстрактных шагов, таких как возьми и принеси губку, но для робота этого не достаточно. Модель SayCan началась переводить инструкции полученные от человека на естественном языке в последовательность понятных команд для робота.
Трансформеры начали использовать для обучения World Models
Исследователи из Женевского университета представили интеллектуального агента IRIS, который учится исключительно в воображении. Модель сначала исследует мир используя обучение в воображении для планирования куда двигаться, а затем используя свои знания о мире учится выполнять какую-то поставленную задачу тоже в воображении. Создатели IRIS показали, что их агент работал эффективно и превосходил человека в 10 из 26 игр Atari. Среди моделей, которые не использовали методов упреждающего поиска, IRIS был лучшим на октябрь 2022г.
Программирование
Лаборатории искусственного интеллекта начали использовать искусственный интеллект для исследования кода.
Codex OpenAI (GitHub Copilot) впечатлил компьютерное сообщество своей способностью завершать код в несколько строк или создавать код непосредственно из инструкций на естественном языке. Этот успех стимулировал дальнейшие исследования в этой области, в том числе от Salesforce, Google и DeepMind. В частности AlphaCode от DeepMind смог занять 1 место на платформе Codeforces (платформа для соревнований по программированию).
Новые возможности моделей
Математические способности
Google дотренировал предобученную модель PaLM на 118 гб научных работ и веб-страницах с LaTeX и MathJax и назвал эту модель Minerva. Она смогла побить SoTA на большинстве датасетов на двузначные цифры(!). Minerva использует только языковую модель и не кодирует в явном виде математику. Поэтому модель может прийти к правильному ответу, используя неправильные шаги рассуждений.
Совсем иной подход был предпринят OpenAI, исследователи смогли построить средство для доказательства теорем в формальной среде Lean. Модель смогла решить несколько задач из школьных олимпиад.
Использование различных программ и инструментов
Языковые модели могут научиться использовать различные инструменты такие, как поисковые системы и калькуляторы. Первой моделью которая научилась пользоваться браузером была WebGPT от OpenAI.
Adept, новая компания AGI, коммерциализирует эту парадигму. Компания обучает большие модели-трансформеры взаимодействию с сайтами, программными приложениями и API-интерфейсами, чтобы повысить производительность рабочего процесса. Это похоже на цифрового помощника в браузере, которого можно попросить купить билет, добавить формулу в google sheets
NeRF
NeRF расширяются в свою собственную зрелую область исследований
Основополагающая статья NeRF была опубликована в марте 2020 года. С тех пор быстро и непрерывно улучшаются фундаментальные методы и новые приложения. Например, в 2022 году на CVPR появилось более 50 статей только по NeRF.
NeRF это …? Мы подаем на вход несколько ракурсов изображения, NeRF изучает отображение каждого пикселя и направления взгляда на цвет и плотность в этом месте, и после обработки всей полученной информации может генерировать новые ракурсы предмета.
Среди работ этого года выделяется Plenoxels, который полностью убрал MLP (multilayered perceptron) и добился 100-кратного ускорения обучения NeRF.
Еще одним захватывающим направлением был рендеринг крупномасштабных пейзажей из нескольких видов с помощью NeRF, будь то в масштабе города (рендеринг целых районов Сан-Франциско с помощью Block-NeRF) или в масштабе спутника с помощью Mega-NeRF.
Медицина
Лечение бактериальных инфекций с помощью персонализированного подбора антибактериальных средств на основе данных
Резистентность к антибактериальным агентам является обычным явлением и часто возникает в результате того, что в организме пациента уже присутствует другой патоген. Так как же врачам подобрать правильный антибиотик, который вылечит инфекцию, но не сделает пациента восприимчивым к новой инфекции?
Исследователи показали, что ML можно использовать для прогнозирования риска развития резистентности, вызванного лечением, на уровне конкретного пациента. Они сравнивая профили микробиома более 200 000 пациентов с инфекциями мочевыводящих путей или раневыми инфекциями, которые лечились известными антибиотиками до и после заражения. Исследователи выяснили пациенты получавшие лечение антибиотиками, которые система ML не рекомендовала бы, приводили к значительной резистентности, в то время как пациенты страдали бы гораздо меньшим количеством повторных инфекций, если бы им прописывали антибиотики в соответствии с системой ML.
Интерпретация масс-спектров малых молекул с использованием трансформеров
Исследователи представили решение для задачи спектрометрической молекулярной идентификации — по масс-спектру вычислить/предсказать двухмерную структуру молекулы, из которой она возникла, особенно остро этот вопрос стоит в метаболомике. Менее 10% малых молекул могут быть идентифицированы из справочных библиотек спектров, поскольку большая часть природного химического пространства неизвестна. Трансформеры обеспечивают быструю и точную характеристику молекул в метаболических смесях (in silico — в симуляции эксперимента), таких как растворимость, сходство с лекарством и синтетическая доступность.
ML может создать новые лекарства … и биохимическое оружие
Исследователи из Collaborations Pharmaceuticals и Королевского колледжа Лондона показали, что модели машинного обучения, предназначенные для терапевтического использования, можно легко перепрофилировать для создания биохимического оружия.
Исследователи натренировали свою модель «MegaSyn», чтобы максимизировать биоактивность и минимизировать токсичность. Для разработки токсичных молекул они сохранили ту же модель, но теперь просто тренировали ее, чтобы максимизировать как биологическую активность, так и токсичность. Они использовали общедоступную базу данных молекул, подобных наркотикам.
Они направили модель на создание нервно-паралитического агента VX, известного как один из самых токсичных боевых отравляющих веществ. Однако, как и в случае с регулярным поиском лекарств, обнаружение молекул с прогнозируемой высокой токсичностью не означает, что их легко создать. Но по мере того, как поиск лекарств с искусственным интеллектом значительно улучшается, то этот передовой опыт в поиске лекарств иожет распространиться на создание дешевого биохимического оружия.