
Нейросеть называется CLIP Guided Giffusion HQ. О чём это нам говорит? HQ — понятно, высокое качество. CLIP (Contrastive Language-Image Pre-Training) — это такой сравнительно новый метод обучения мультимодальных нейросетей. Мультимодальность в данном случае означает одновременную обработку разных типов данных — текста и изображения. Предыдущие сети, умевшие рисовать картинки, в основном относились к типу GAN (генеративно-состязательные). У этого подхода есть свои плюсы и минусы, ну да сейчас не о нём. Diffusion означает диффузионный метод формирования изображения, при котором из «затравочной» картинки поэтапно удаляется шум. Затравка может быть осмысленным изображением или случайным набором пикселей.
Для начала небольшая справка. Нейросеть называется CLIP Guided Giffusion HQ. О чём это нам говорит? HQ — понятно, высокое качество. CLIP (Contrastive Language-Image Pre-Training) — это такой сравнительно новый метод обучения мультимодальных нейросетей. Мультимодальность в данном случае означает одновременную обработку разных типов данных — текста и изображения. Предыдущие сети, умевшие рисовать картинки, в основном относились к типу GAN (генеративно-состязательные). У этого подхода есть свои плюсы и минусы, ну да сейчас не о нём. Diffusion означает диффузионный метод формирования изображения, при котором из «затравочной» картинки поэтапно удаляется шум. Затравка может быть осмысленным изображением или случайным набором пикселей.

Типичная затравка. Когда б вы знали, из какого сора…
Примечательно, что CLIP Guided Giffusion HQ была обучена не на заранее размеченных наборах данных, а на 400 миллионах пар «картинка-текст», взятых просто из интернета. Да, мемы с котиками, рисунки фурей с Deviantart и предвыборные плакаты Трампа — всё это сеть впитала в себя, словно дух реки из «Унесённых призраками». Причём алгоритм сам определял, какой текст к какой картинке относится, что привело к некоторым любопытным особенностям. Чтобы хоть немножко «окультурить» нейронку, авторы вручную добавили в датасет ещё 500 тысяч изображений, которые ищутся по словам из заголовков статей английской Википедии.
Но довольно теории, ведь все понимают, ради чего мы тут собрались, — ради наркоманских картиночек, конечно же! Попробовать CLIP Guided Giffusion HQ можно много где. Естественно, все вычисления будут выполняться не на вашем компьютере, а на удалённой виртуальной машине. Код требует мощного графического ускорителя с кучей памяти. Нет, можно запускать и на CPU, но тогда результат работы увидят только ваши внуки.
Для начала предлагаю попробовать простой веб-интерфейс, позволяющий немного поиграть шрифтами параметрами.
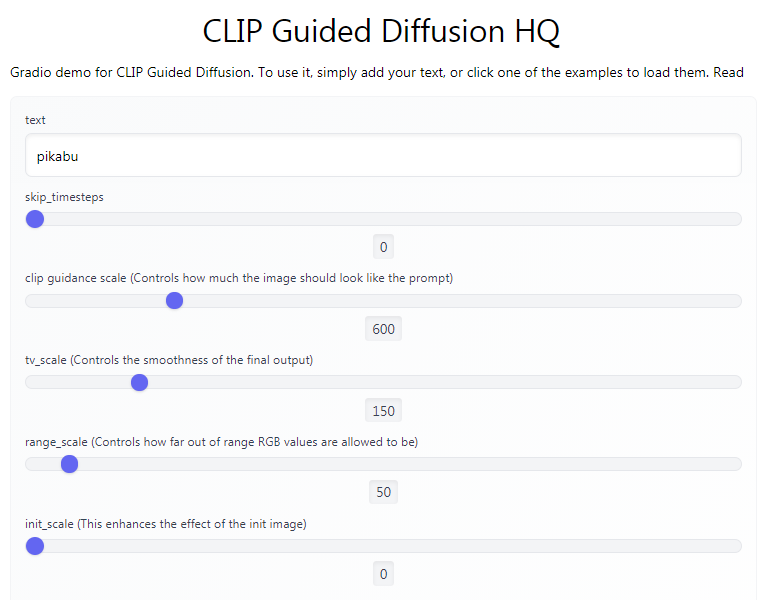
Запрос вводится в поле text, ползунок timestep respacing задаёт количество итераций (чем больше, тем проработаннее будет картинка), остальные параметры первое время можно не трогать. Нажимаем [Submit], ждём несколько минут и получаем свою дозу ЛСД размером 256 × 256 пикселей. Да, негусто, но таковы ограничения используемого датасета и доступной аппаратуры. О том, как можно поднять разрешение, мы ещё поговорим в конце поста.
Вот так, по мнению нейросети, выглядит «pikabu».

Не спрашивайте меня, почему он похож на чёрную дождевую лягушку с анальной пробкой!

Искусственный интеллект так видит. И вообще, сначала сочини симфонию и преврати кусок холста в шедевр искусства, а потом уже возмущайся!
Абстрактные пейзажи удаются CLIP Guided Giffusion HQ намного лучше. Например, вот эту иллюстрацию по запросу «Песнь льда и пламени» (естественно, по-английски) можно хоть сейчас ставить на обложку метал-альбома.

Кстати, насчёт перевода. Мне стало любопытно, не было ли в обучающей выборке текстов на кириллице. Я сформулировал максимально простой запрос, по которому было бы очевидно, поняла меня сеть или нет, — «синий треугольник». В общем, не повторяйте моих ошибок!

Теперь этот мужик будет являться ко мне во снах.
Если написать тот же текст латиницей, результат будет не лучше. Хоба!

В общем, про русский язык можно забыть.
По запросу «steampunk» удалось получить затейливые узоры из латунных трубок и клапанов, эдакий Царь-саксофон.

Но в целом с техникой нейросеть справляется плохо. Сколько раз я ни просил её нарисовать самолёт, паровоз или танк, получалась какая-то ерунда.
Не стоит ждать от неё и угадывания того, что именно вы имеете в виду. Скажем, вводя запрос «Heroes III», я был уверен, что получу какую-то вариацию на тему скриншотов из игры. А получил вот что:

Ну, тут отдалённо угадываются фигуры в доспехах и с оружием… Видимо, это герои. Три штуки!
Любопытные картинки получаются, когда сети попадаются слова с множественными значениями. Скажем, «Red Square» — и «Красная площадь», и «красный квадрат». Нейросеть не могла знать, что именно от неё хотят, поэтому на всякий случай сгенерировала картинку «и нашим, и вашим» — красный квадрат, но со структурой брусчатки.

Ещё немного крипоты по запросу The Hound of the Baskervilles.

«Это я, сэр Генри. Помоги выбраться из собаки!»
Понимания культурного контекста кремниевым мозгам, конечно, не хватает. Я предложил сетке сгенерировать обложку для книги «Снятся ли андроидам электроовцы?». В результате получилось изображение с двумя подключёнными к электросети смартфонами (видимо, на Android), на экране которых изображены овцы.

— Какие претензии? Андроиды есть? Есть. Овцы есть? Есть. Электрические? Ну так ясен хрен, что не живые! Иди отсюда, кожаный мешок, ты сам не знаешь, чего хочешь!
Впрочем, в чём слабость сети, в том и её сила (простите, что заговорил цитатами из пацанских пабликов). Она честно пытается интерпретировать все слова, которые вы включили в запрос, и если ей знакомо что-то похожее, может получиться очень интересный результат. Нет никаких формальных правил, просто вписывайте туда всё, что придёт в голову. Например, добавляя в конце by <имя_художника>, можно получать картины в его стиле.

Harry Potter by Wassily Kandinsky и Robinson Crusoe by Claude Monet
Если нужен конкретный цвет, это тоже можно добавить в запрос — скорее всего, сработает. Повторю фрагмент стартовой картинки:
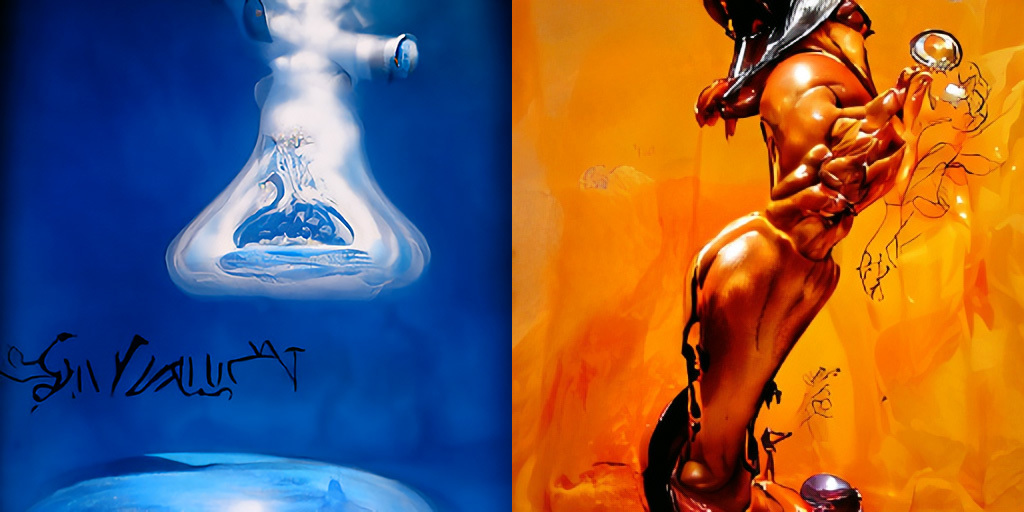
1. Scientific certainity by Salvador Dali in blue
2. Alchemist by Boris Vallejo in orange
Остальные две иллюстрации, если что, это The Picture of Dorian Gray by Giuseppe Arcimboldo и The Lord of the Rings by Arnold Böcklin.
Если требуется дорисовать (ну или сделать более наркоманской) существующую картинку, её нужно добавить в поле initial image. Параметр skip_timesteps влияет на то, на сколько итераций нейросеть может уйти в своих фантазиях от предложенного образа, а clip guidance scale определяет, насколько строго его нужно придерживаться.
Хороший результат получается не всегда. Скажем, попытка скрестить образы Бога-Императора и Владимира Путина лишь сделала Императора более недовольным.

Была и другая картинка по тому же тексту, но её я покажу, только если очень-очень попросите.
I need MOAR!
Если вам мало возможностей huggingface.co, советую обратиться к оригинальному коду авторства Katherine Crowson. Заходите сюда под гугл-аккаунтом, нажимайте «Подключиться» в правом верхнем углу и надейтесь, что вам не выпадет сообщение о том, что доступен только центральный процессор. Если же вам предоставили GPU, самое время заглянуть в зубы дарёному коню. Для этого поставьте курсор на первый блок кода и нажмите Ctrl+Enter, чтобы выполнить его. На экране появится информация о графическом ускорителе виртуальной машины.
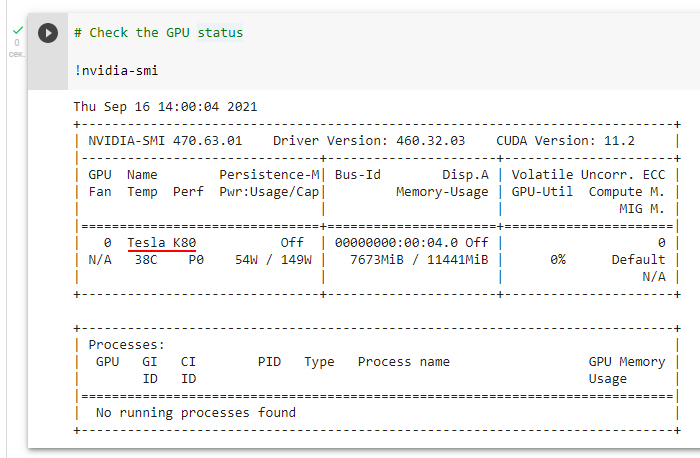
Скорее всего, вам достанется средней паршивости Tesla K80, на котором картинка в хорошем качестве считается полчаса–час. Но если повезёт (чаще всего это бывает ночью), можно заполучить и Tesla T4, а это уже означает ускорение почти на порядок плюс некоторые дополнительные возможности, о которых я скажу далее.
Чтобы шестерёнки завертелись, нажимайте Ctrl+F9 (ну или [Среда выполнения → Выполнить всё]). Потребуется время на установку необходимых пакетов и скачивание самой модели, обычно в пределах десяти минут. Изредка нужно проявлять активность в этой вкладке, иначе Google будет ругаться, что вы зря тратите его ресурсы.
Основные параметры задаются в блоке Settings for this run.
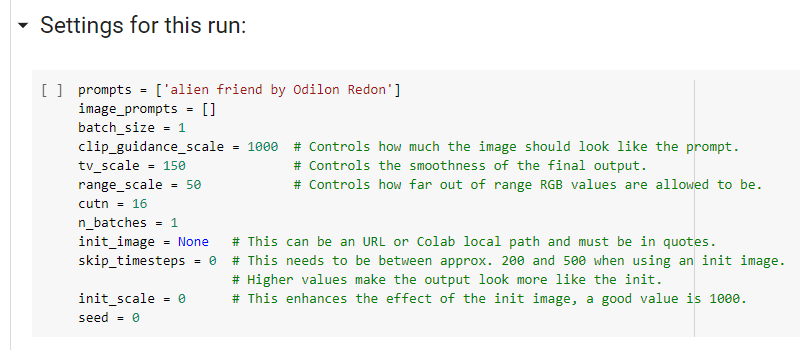
Если вы хотите работать только с текстом, ничего кроме prompts вам не нужно. Если же требуется стартовая картинка, вставьте её URL в одинарных кавычках вместо None вот сюда:
init_image = None. Также рекомендую для начала skip_timesteps = 300 и init_scale = 1000.
Количество итераций задаётся в блоке Model settings параметром timestep_respacing. Значение должно быть в одинарных кавычках.
Я бы для начала ставил 500 или даже 250, особенно если вам достался слабый ускоритель. 1000 необходимо для максимальной проработки и звенящей чёткости деталей.
Кстати, о чёткости. Как я уже говорил, эта сеть умеет делать картинки размером только 256 × 256. Задача сгенерировать изображение по тексту очень сложна, так что даже на одну такую картинку уходит больше вычислений, чем в своё время потребовал весь атомный проект СССР. Но вот задача увеличить разрешение с сохранением чёткости куда проще, и её вполне можно перепоручить другой нейросети. Тут я уже не буду подробно расписывать, можно почитать обзор и выбрать понравившуюся. Есть полностью бесплатные, есть с триальным периодом. Некоторые иллюстрации прямо сильно выигрывают от апскейла.

«Квантовый портал в стиле Сталкера», увеличение 4x через deep-image.ai
Мой друг, который на досуге пишет фантастическую литературу, всерьёз задумался, не иллюстрировать ли ему свои книги при помощи нейросетей.
Ну и, наконец, о дополнительных возможностях, которые дарует ускоритель Tesla T4. У него 16 ГБ памяти, а это значит, что на нём можно запускать продвинутую версию той же нейросети, которая сразу генерирует картинки размером 512 × 512 пикселей. Доступна тут.
Вообще у нейросетей, основанных на методе CLIP, есть много вариаций. Я показал только три самые простые, с которыми можно быстро начать работу. Но если поискать, вы найдёте и другие.
Ещё раз основные ссылки для ЛЛ:
3. Если повезёт заполучить Tesla T4